摘要
微信域名检测自动化 HTTP 服务脚本,可检测域名在微信内是否被封或被拦截。
支持检测情况包括:
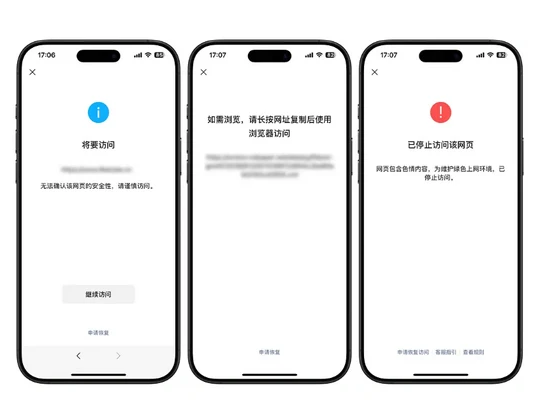
如需浏览,请长按网址复制后使用浏览器访问已停止访问该网页将要访问非官方网页未备案技术原理
使用Python脚本自动化控制微信电脑版,完成访问网页的过程,解析页面内容,即可得到检测结果。
优点:准确;缺点:需要挂机、并且响应速度慢,大概需要3-5秒完成一次检测;检测结果颜色页面 Title页面 Desc检测结果???? 红色拦截已停止访问该网页网页包含 XXX 内容,为维护绿色上网环境,已停止访问。拦截???? 蓝色封禁将要访问非微信官方网页,请确认是否继续访问。拦截⚪ 白色封禁如需浏览,请长按网址复制后使用浏览器访问页面 URL拦截???? 以上情况均可检测出结果。如何使用
登录微信电脑版版本要求:最新版 Windows 微信(版本号 4.1.0.18)
打开任意网页窗口保持最小窗口左上角到搜索框中间位置:265 像素示例截图:

代码
import uiautomation
as auto
import pyautogui
import time
import json
from http.server
import BaseHTTPRequestHandler, HTTPServer
from urllib.parse
import urlparse, parse_qs
import pyperclip
def find_all_controls(
control, results=None):
"""递归收集所有控件"""
if results
is None:
results = []
try:
if control.Exists(
0.1):
results.append(control)
try:
children = control.GetChildren()
except:
children = []
for child
in children:
find_all_controls(child, results)
except Exception:
pass
return results
def automate_url(
url):
"""执行点击输入URL和获取控件逻辑"""
class_name_to_search =
"Chrome_WidgetWin_0"
desktop = auto.GetRootControl()
controls = [c
for c
in desktop.GetChildren()
if c.ClassName == class_name_to_search]
for ctrl
in controls:
try:
rect = ctrl.BoundingRectangle
x = rect.left +
275
y = rect.top +
15
pyautogui.moveTo(x, y, duration=
0.3)
pyautogui.click()
pyperclip.copy(url)
pyautogui.hotkey(
"ctrl",
"v")
pyautogui.press(
"enter")
time.sleep(
2)
all_controls = find_all_controls(ctrl)
text_controls = [c.Name
for c
in all_controls
if c.ControlTypeName ==
"TextControl" and c.Name]
if text_controls:
title_text = text_controls[
0]
desc_text =
",".join(text_controls[
1:])
if len(text_controls) >
1 else ""
else:
title_text =
""
desc_text =
""
blocked_phrases = [
"如需浏览,请长按网址复制后使用浏览器访问",
"已停止访问该网页",
"将要访问"
]
if any(phrase
in title_text
for phrase
in blocked_phrases):
return {
"code": -
1,
"msg":
"拦截",
"url": url,
"ret": {
"title": title_text,
"desc": desc_text}}
else:
return {
"code":
0,
"msg":
"正常",
"url": url,
"ret": {
"title": title_text,
"desc": desc_text}}
except Exception
as e:
return {
"code": -
2,
"msg":
f"操作失败: {e}",
"url": url,
"ret": {
"title":
"",
"desc":
""}}
class MyHandler(
BaseHTTPRequestHandler):
def do_GET(
self):
parsed_path = urlparse(
self.path)
query = parse_qs(parsed_path.query)
url = query.get(
"url", [
""])[
0]
if not url:
self.send_response(
400)
self.send_header(
"Content-type",
"application/json")
self.end_headers()
self.wfile.write(json.dumps({
"code": -
3,
"msg":
"缺少url参数"}).encode(
"utf-8"))
return
result = automate_url(url)
self.send_response(
200)
self.send_header(
"Content-type",
"application/json")
self.end_headers()
self.wfile.write(json.dumps(result, ensure_ascii=
False).encode(
"utf-8"))
if __name__ ==
"__main__":
host =
"127.0.0.1"
port =
8000
print(
f"服务器启动: http://{host}:{port}")
server = HTTPServer((host, port), MyHandler)
server.serve_forever()启动HTTP服务python weixin_domain_check.py浏览器访问
http:/
/127.0.0.1:8000/?url=你要检测的域名或链接